

データサイエンスの研究
1. 研究開発のねらい
研究開発の加速・成果増進、ビジネスの課題解決・意思決定改善を実現するために、データサイエンスの研究に取り組んでいます。
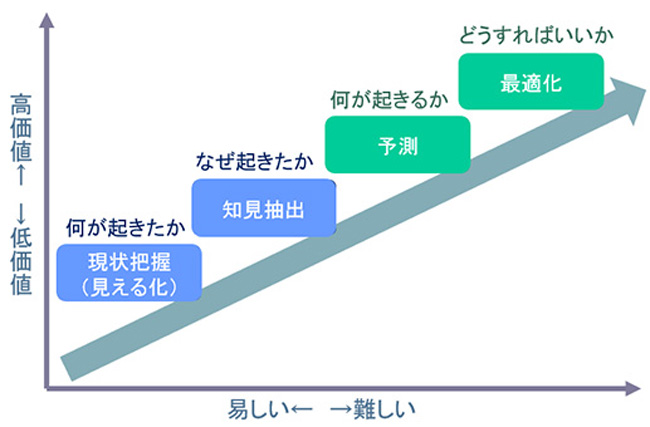
〇データ活用の4段階
ガートナーの分析成熟度モデル(Analytic Ascendancy Model)を参考に、データ活用を4段階で捉えています。
- ①現状認識:データを収集して、起きている“事実”を観測する
- ②知見抽出:“事実”から、原因や関係性、特異な事象など、役に立つ“知見”を得る
- ③予測:「過去の傾向が未来も続く」という仮定のもとで、未来を“予測”する
- ④最適化:現実をコンピューター上で再現して、与えられた条件下での“最適解”を導く
右上のものほど、高価値ですが、難度が高く、大量・高精度なデータが必要になります。
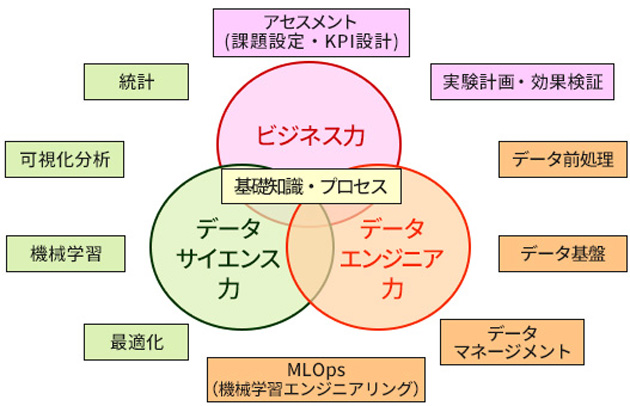
〇データサイエンスの技術整理
これらデータ活用を実現するための技術がデータサイエンスになります。図のような「データサイエンスのベン図」を元に、以下の取り組みを進めています。
- 必要な技術の整理、優先度順位付け
- 利用環境整備、技術修得
- データ分析による成果の創出
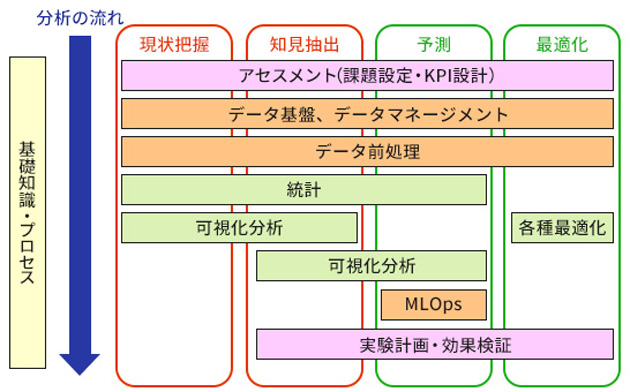
2. 取り組み内容
(1)アセスメント
データ活用における要件定義にあたるもので、これの確度がデータ活用プロジェクトの成否を分ける重要な工程になります。研究/ビジネス課題を整理・具体化し、適切なデータ分析課題に落とし込むとともに、効果規模・費用対効果や実務利用の姿の見立てなどを行い、実施判断を行います。
検討事項や進め方のガイドラインを作成して、成功率を高めるよう取り組んでいます。
(2)可視化分析
研究開発で扱うヒト・機器のセンサー取得データや、ビジネスの様々なデータに対し、それを見ることを通じて実体を把握し、分析対象であるモノや事象の理解を深めます。
“BI”(ビジネスインテリジェンス)ツールを用いて集計やグラフにすることで、ヒトの理解を助け、ビジネス的に価値のある知見を発見しています。
(3)機械学習
多種多様・大量のデータから、ヒトが法則性を見つけ出すのは困難ですが、いわゆるAI(人工知能)の主要技術である機械学習(マシーンラーニング)を使うことで、それが可能となります。“オートML”(機械学習モデル自動作成)ツールを用いることで、比較的低い学習コストで、効率的に機械学習の活用を実現しています。
また、機械学習の開発工程の標準化にも取り組んでいます。
(4)データ基盤
エネルギーの需要データや、設備機器などのセンサーデータは、億~十億の桁の規模のビッグデータとなるため、従来のデータベースやワークステーションでは、処理に膨大な時間がかかってしまいます。これに対し、クラウドデータ基盤サービスを利用することで、高速・効率的なデータ処理を実現しています。
3. まとめ
データ活用は、企業のDX・デジタル化に必須となっています。統計・数理の専門知識を基に、研究開発におけるデータ活用の実践を通して得られたノウハウや情報資産を、ビジネスにおけるデータ活用支援や人材育成にフィードバックしています。